FashionAI—服饰属性标签识别数据集
Background
Upgrades in consumption patterns mean that there is significant room for potential growth in the fashion industry. According to official statistics from different countries, the market value of the global apparel market is worth over USD 3 trillion. Although artificial intelligence (AI) technology has been evolving along with the fashion industry, there are still different challenges in different areas that need to be addressed.
To promote the development of the fashion industry, the Vision & Beauty Team of the Alibaba Group and the Institute of Textile and Clothing of The Hong Kong Polytechnic University are pleased to jointly launch a revolutionary fashion AI dataset which integrates both professional fashion knowledge and machine learning formulation.
The Attributes Recognition of Apparel dataset is part of the fashion AI dataset mentioned above. Apparel attributes are the basic knowledge of fashion field, which are large and complex. We constructed a hierarchical attributes tree as a structured classification target, to describe the cognitive process of apparel. Researchers are invited to design algorithms to recognize attributes of apparel images. This task might be widely applied for apparel image searching, navigating tagging, mix-and-match recommendations, etc.
Introduction
Apparel attributes are the basic knowledge of fashion field, which are large and complex. We constructed a hierarchical attributes tree as a structured classification target, to describe the cognitive process of apparel. You are invited to design algorithms to recognize attributes of apparel images. This task might be widely applied to apparel image searching, navigating tagging, mix-and-match recommendation, etc.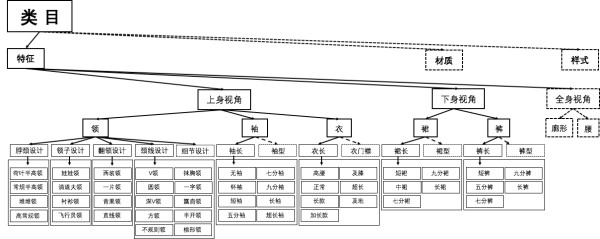
Figure 1. Architecture of the apparel attributes used in the task
Data Description
Terminology
a) Attribute Dimension (AttrKey): A specific apparel attribute, e.g. sleeve length.
b) Attribute Value (AttrValues): The specific value under a specific attribute dimension, e.g. short-length and mid-length under the dimension of sleeve length.
Image data
All image data are from Alibaba e-Commerce platform.
This task aims at apparel attribute recognition. All distinguishable apparel attribute labels in Figure 1 are required to be detected. With the consideration of the complexity of fashion knowledge, only single-subject (single-model or tiled single-piece) product images are used in this challenge. Researchers can thus focus on the task of recognizing each fine-grained apparel attribute.
Labels
a) The above image data are labeled by well-trained annotators. These labels are then double-checked by fashion experts to guarantee a high labeling accuracy. A certain amount of missing-labels exist in the annotated data. For instance, there may only be a neck design label in an image with visible neck design and sleeves length. The sleeves length is no longer labeled to maintain the evenness of data for each attribute dimension.
b) Eight major attribute dimensions are selected for this track, namely neckline design, collar design, high neck design, lapel design, sleeves length, length of top, length of skirt, and length of trousers.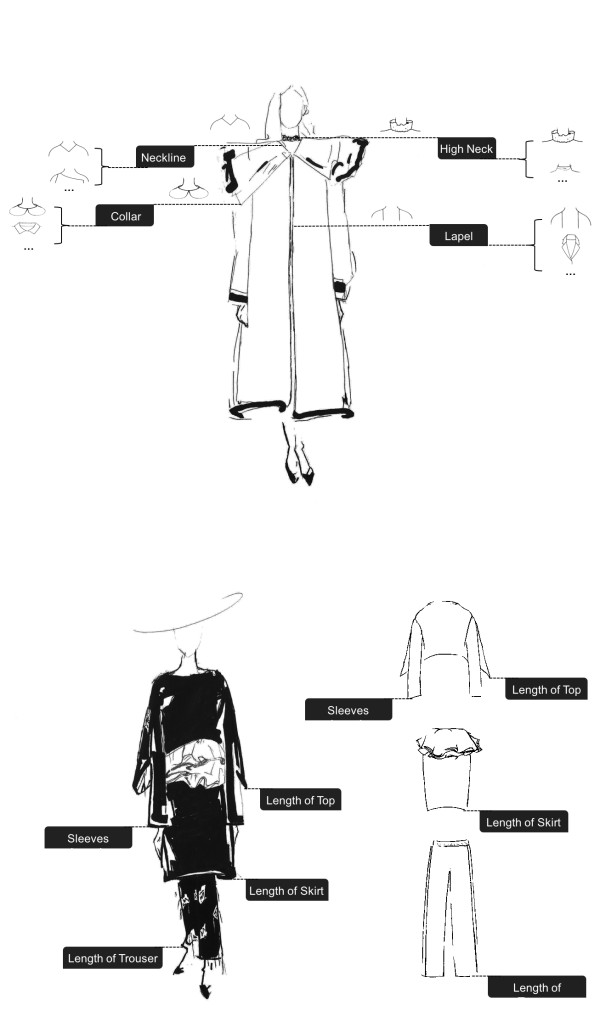
Figure 2. Demonstration of the attributes on model
Data Characteristics
a) Mutual exclusion: Attribute values under a specific attribute dimension are mutually exclusive. For example, in high neck design dimension, a high-collar and a ruffle semi-high collar cannot coexist in the same image. One thing has to be noticed: Considering the rigor of the challenge, to guarantee the mutual exclusion of attribute, we abandoned some specific images in which a model wears several overlaid apparel items and thus generates several different attributes in one dimension.
b) Independence: Attribute values under different dimensions can coexist in the single image, and they are independent of each other. For instance, “neck-high neck design-turtle neck” and “neck-collar design-shirt collar” can coexist in a single image.
c) Under each attribute dimension, there is an “invisible” value. It means that a particular attribute is defined in the perspective (top look, bottom look or body look) but does not appear or is occluded in the specific image. For example, given an image of a model wearing a dress as shown in Figure 5, this image contains two perspectives, top look and bottom look. The hemline of the skirt is occluded, so the dress length dimension will be labeled as “invisible”. The algorithm should take such kind of “negation” into consideration. But we will not examine the negation ability for attributes that are not defined in the corresponding perspectives. For example, like a pant image that has only the bottom look (in Figure1), we will not examine its attributes (like "sleeve length") of the top look.
Dataset
Train Data
The train dataset contains the following files: round1_fashionAI_attributes_train.tar(train data of the preliminary stage), round1_fashionAI_attributes_test_A.tar(testA data of the preliminary stage + answer), round1_fashionAI_attributes_test_B.tar(testB data of the preliminary stage + answer), round2_fashionAI_attributes_train.tar(train data of the semi-final stage)
File structure of the training data
Image data and annotated labels of the training set are provided in the following structure:
o Images
o Annotations
o README.md
a) The “Images” folder has image data in JPEG format. For example, an image can be named as “0000001.jpg”.
b) The “Annotations” folder has annotated attribute labels in csv format.
c) README.md: a detailed introduction to the above data.
An example of the training data
Figure 3. Demonstration of the apparel attributes of training data
The csv file corresponding to the example of Fig.3: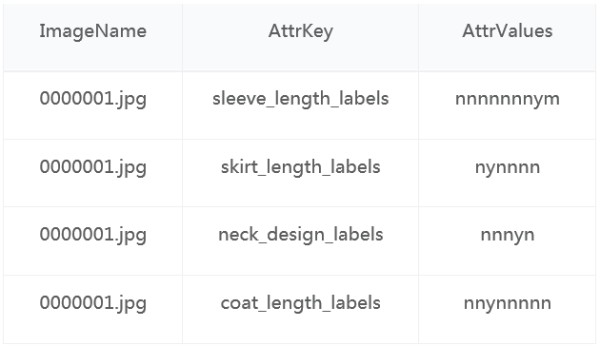
The format of the annotation file
ImageName: the image name corresponding to a specific image file in “Images” folder.
AttrKey: the attribute dimension, such as sleeve length (sleeve_length_labels), trousers length (pant_length_labels), etc.
AttrValues: the attribute values corresponding to an attribute dimension in AttrKey. For example, there are nine values in the sleeves length dimension: invisible, sleeveless, cup sleeve, short sleeve, mid length, 3/4 sleeve, wrist length sleeve, long sleeve and extra-long sleeve which are corresponding to the “nnnnnnmyn” annotation in the figure above. The annotations contain nine digits in total, with each digit representing one of the three letters below: y(means “yes”, “must be”), m(means “may be”, “probably”), and n(means “no”, “must not be”). For each attribute dimension in a given image, there can be one and only one “y” annotated digit, the other digits can be either “m” or “n”.
All AttrKeys and corresponding AttrValues are specified in README.md.
Definition of the ambiguous border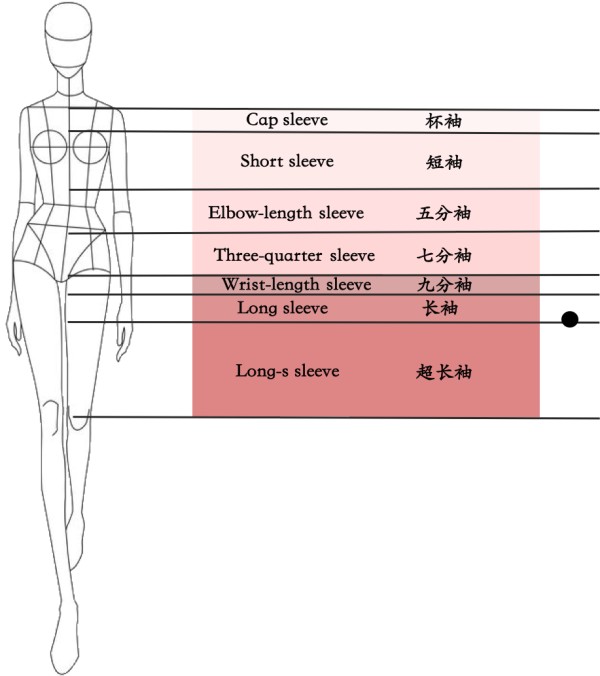
Figure 4. Demonstration of the ambiguous border
Ambiguity occurs in the above example figure. In particular, the sleeve length is in between “long sleeve” and “extra-long sleeve”, but the former weighs slightly more than the later. In this case, the “long sleeve” digit is annotated as “y”, and “extra-long sleeve” digit is annotated as “m”, and the remaining digit is “n”.
Such ambiguity occurs frequently and is unavoidable in real-world apparel attribute annotation.
Definition of occlusion
Figure 5. Demonstration of occlusion
Occlusion is also unavoidable in apparel attribute annotation.
In the above example image, the hemline of the dress is cropped, and thus it is hard to accurately predict the dress length. In this case, the “invisible” digit should be labeled as “y” and the other digits labeled as “n”. Therefore, the “skirt_length_labels” is annotated as “ynnnnn”.
Test Data
The test dataset contains the following files: round2_fashionAI_attributes_test_A.tar(testA data of the semi-final stage), round2_fashionAI_attributes_test_B.tar(testB data of the semi-final stage).
We also provide a long-term leaderboard for researchers to validate their model's performance: https://tianchi.aliyun.com/competition/entrance/231671/information. Note: the datasets provided with the leaderboard are a subset of the FashionAI - Attributes Recognition of Apparel Dataset, specific to say, fashionAI_attributes_train1.zip - round1_fashionAI_attributes_train.tar, fashionAI_attributes_train2.zip - round2_fashionAI_attributes_train.tar, fashionAI_attributes_test.zip - round2_fashionAI_attributes_test_B.tar.
a) The file structure is as follows:
o Images
o Test
o README.md
b) The “Images” folder has image data in JPEG format. For example, an image can be named as “0000001.jpg”.
c) The “Test” folder has the attribute dimension information on which contestants are required to conduct a prediction. Contestants should predict and deliver a probability for each attribute value. As a result, all “?” position will be replaced by a predicted probability (in fractional format). The attribute value with maximum probability will be chosen as the prediction result for each attribution dimension. The attribute information file (.csv files) is in the following format: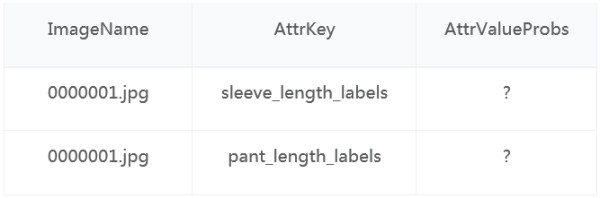
d) README.md: a detailed introduction to the above data.
Data to be submitted
Researchers can predict the probability for the AttrValueProbs field. Please refer to the sample csv file in the “Test” folder: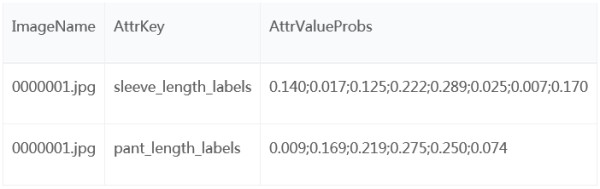
Explanation of each item:
a) ImageName: names of image files in “Images” folder
b) AttrKey: attribute dimension, such as sleeve length (sleeve_length_labels)
c) AttrValueProbs: the predicted probability of each attribute value. It will be used to compute mean average precision (mAP) for algorithm evaluation.
Evaluation
mAP is used for the evaluation metric for this task. the mAP value is computed as follows:
Read the predicted csv file , and find out the attribute value with maximum probability for each prediction. Record this attribute value and its corresponding probability to MaxAttrValue and MaxAttrValueProb, respectively. For each attribute dimension, initialize its counter:BLOCK_COUNT = 0 (the number of blocked data)
PRED_COUNT = 0 (the number of predicted data)
PRED_CORRECT_COUNT = 0 (the number of correctly predicted data)
We assume GT_COUNT is the total number of data related to this attribute dimension. Given a ProbThreshold as the threshold of output, analyze each predicted result related to this attribute dimension:
When MaxAttrValueProb < ProbThreshold, there is no output:
BLOCK_COUNT++
When MaxAttrValueProb > = ProbThreshold:
If the digit corresponding to MaxAttrValue is annotated as “y”, the prediction is correct: PRED_COUNT++, PRED_CORRECT_COUNT ++;
If the digit corresponding to MaxAttrValue is annotated as “m”, nothing happens.
If the digit corresponding to MaxAttrValue is annotated as “n”, the prediction is wrong: PRED_COUNT++ Iterate over all possible thresholds which make BLOCK_COUNT cover [0, GT_COUNT), and calculate:
Precision (P): PRED_CORRECT_COUNT / PRED_COUNT
Compute the mean of all Precision(P)s above, denoted as AP. Compute the mean of APs of all attribute dimensions to obtain mAP. mAP is used as the ultimate ranking score for the apparel attribute recognition dataset.
Note: We also provide a Java-implemented evaluation script eval.zip for reference.
Citation
Please cite the following paper for acknowledgement:
@INPROCEEDINGS{9025573, author={Zou, Xingxing and Kong, Xiangheng and Wong, Waikeung and Wang, Congde and Liu, Yuguang and Cao, Yang}, booktitle={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, title={FashionAI: A Hierarchical Dataset for Fashion Understanding}, year={2019}, volume={}, number={}, pages={296-304}, doi={10.1109/CVPRW.2019.00039}}
License
The dataset is distributed under CC BY-NC 4.0 license.
Recommend Dataset
Fashion Clothes Matching CTR Prediction Dataset:https://tianchi.aliyun.com/dataset/dataDetail?dataId=131519
FashionAI - Attributes Recognition of Apparel Dataset:https://tianchi.aliyun.com/dataset/dataDetail?dataId=136923
FashionAI - Key Points Detection of Apparel Dataset: https://tianchi.aliyun.com/dataset/dataDetail?dataId=136948
Clothes Matching Dataset on Taobao:https://tianchi.aliyun.com/dataset/dataDetail?dataId=52
网址:FashionAI—服饰属性标签识别数据集 http://www.mxgxt.com/news/view/1105705
相关内容
人脸识别数据集整理深度解析:常见明星人脸识别数据集及其应用
探索模特与明星人脸数据集:解锁人脸识别新应用
基于多源数据融合的船舶位置识别方法.pdf
人脸识别技术下的明星数据探讨与隐私保护
2023服装配饰行业明星与社媒营销数据洞察.pdf
北京主线科技申请数据标注方法专利,提高数据标注的准确性和可靠性
数据可视化系列
2023服装配饰行业明星与社媒营销数据洞察报告
刘仁文:去有罪标签 禁穿囚服还不够
随便看看
最新实时动态
- 原生家庭的影响:众多空心孩子的成长故事
- 韩雪的家庭背景与成长经历揭秘
- 明星年赚上亿不合理,社会环境亦是教育环境,引领好青少年的三观
- 无爱环境长大的他,23岁帅气不减,简直不可思议!
- 杜江个人资料简介(身高/生日/年龄)
- 高鑫个人资料简介(身高/生日/年龄)
- 董勇个人资料简介(身高/生日/年龄)
- 王天辰个人资料简介,主演的电视剧电影,图片,写真
- 张璇个人资料简介,主演的电视剧电影,图片,写真
- 邵兵个人资料简介(身高/生日/年龄)
热点实时动态
- 11465
- 7346
- 7155
- 6995
- 6963
- 6672
- 6238
- 6059
- 6058
- 6039

