StarRocks 【新一代MPP数据库】(2)
2024-06-11 421 发布于黑龙江
版权
举报
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《 阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写 侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
StarRocks 【新一代MPP数据库】(1)https://developer.aliyun.com/article/1534279
2、StarRocks 表设计
2.1、列式存储
StarRocks的表和关系型数据相同, 由行和列构成. 每行数据对应用户一条记录, 每列数据有相同数据类型. 所有数据行的列数相同, 可以动态增删列. StarRocks中, 一张表的列可以分为维度列(也成为key列)和指标列(value列), 维度列用于分组和排序, 指标列可通过聚合函数SUM, COUNT, MIN, MAX, REPLACE, HLL_UNION, BITMAP_UNION等累加起来. 因此, StarRocks的表也可以认为是多维的key到多维指标的映射.
在StarRocks中, 表中数据按列存储, 物理上, 一列数据会经过分块编码压缩等操作, 然后持久化于非易失设备, 但在逻辑上, 一列数据可以看成由相同类型的元素构成的数组. 一行数据的所有列在各自的列数组中保持对齐, 即拥有相同的数组下标, 该下标称之为序号或者行号. 该序号是隐式, 不需要存储的, 表中的所有行按照维度列, 做多重排序, 排序后的位置就是该行的行号.
查询时, 如果指定了维度列的等值条件或者范围条件, 并且这些条件中维度列可构成表维度列的前缀, 则可以利用数据的有序性, 使用range-scan快速锁定目标行. 例如: 对于表table1: (event_day, siteid, citycode, username)➜(pv); 当查询条件为event_day > 2020-09-18 and siteid = 2, 则可以使用范围查找; 如果指定条件为citycode = 4 and username in ["Andy", "Boby", "Christian", "StarRocks"], 则无法使用范围查找.(因为它的第一个条件的字段是 citycode 对应不上 starrocks 的第一个维度列,所以就无法优化查询速度)所以我们在查询的时候需要尽量遵守这个规则。
2.2、稀疏索引
当进行范围查询时,StarRocks如何快速定位到起始目标行呢?答案是使用shortkey index. shortkey index为稀疏索引。
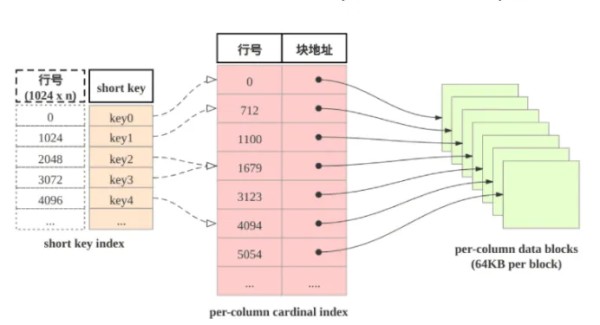
表中组织由三个部分组成:
(1)shortkey index表: 表中数据每1024行, 构成一个逻辑block. 每个逻辑block在shortkey index表中存储一项索引, 内容为表的维度列的前缀, 并且不超过36字节. shortkey index为稀疏索引, 用数据行的维度列的前缀查找索引表, 可以确定该行数据所在逻辑块的起始行号.
(2)Per-column data block: 这是实际存储数据的物理块(经过压缩)。表中每一列数据按64KB分块存储, 数据块作为一个单位单独编码压缩, 也作为IO单位, 整体写回设备或者读出.
(3)Per-column cardinal index: 专门存放地址。表中的每列数据有各自的行号索引表, 列的数据块和行号索引项一一对应, 索引项由数据块的起始行号和数据块的位置和长度信息构成, 用数据行的行号查找行号索引表, 可以获取包含该行号的数据块所在位置, 读取目标数据块后, 可以进一步查找数据.
由此可见, 查找维度列的前缀的查找过程为: 先查找shortkey index, 获得逻辑块的起始行号, 查找维度列的行号索引, 获得目标列的数据块, 读取数据块, 然后解压解码, 从数据块中找到维度列前缀对应的数据项.
2.3、加速数据处理
(1)预先聚合: StarRocks支持聚合模型, 维度列取值相同数据行可合并一行, 合并后数据行的维度列取值不变, 指标列的取值为这些数据行的聚合结果, 用户需要给指标列指定聚合函数. 通过预先聚合, 可以加速聚合操作.
(2)分区分桶: 事实上StarRocks的表被划分成tablet, 每个tablet多副本冗余存储在BE上, BE和tablet的数量可以根据计算资源和数据规模而弹性伸缩. 查询时, 多台BE可并行地查找tablet快速获取数据. 此外, tablet的副本可复制和迁移, 增强了数据的可靠性, 避免了数据倾斜. 总之, 分区分桶保证了数据访问的高效性和稳定性.
(3)RollUp表索引: shortkey index可加速数据查找, 然后shortkey index依赖维度列排列次序. 如果使用非前缀的维度列构造查找谓词, 则无法使用shortkey index. 用户可以为数据表创建若干RollUp表索引, RollUp表索引的数据组织和存储和数据表相同, 但RollUp表拥有自身的shortkey index. 用户创建RollUp表索引时, 可选择聚合的粒度, 列的数量, 维度列的次序; 使频繁使用的查询条件能够命中相应的RollUp表索引.
(4)列级别的索引技术: Bloomfilter可快速判断数据块中不含所查找值, ZoneMap通过数据范围快速过滤待查找值, Bitmap索引可快速计算出枚举类型的列满足一定条件的行.
2.4、数据模型
目前StarRocks根据摄入数据和实际存储数据之间的映射关系,分为明细模型(Duplicate key)、聚合模型(Aggregate key)、更新模型(Unique key)和主键模型(Primary key)。
四中模型分别对应不同的业务场景
2.4.1、明细模型明细模型是默认的建表模型。如果在建表时未指定任何模型,默认创建的是明细类型的表。它就像我们数仓中的 ODS 层或者 DWD 层,也就是说这个表中存储的是一些明细数据(比如用户的所有下单记录)。
StarRocks建表默认采用明细模型,排序列使用稀疏索引,可以快速过滤数据。明细模型用于保存所有历史数据,并且用户可以考虑将过滤条件中频繁使用的维度列作为排序键,比如用户经常需要查看某一时间,可以将事件时间和事件类型作为排序键。
mysql> create database test_db; mysql> use test_db; CREATE TABLE IF NOT EXISTS detail ( event_time DATETIME NOT NULL COMMENT "datetime of event", event_type INT NOT NULL COMMENT "type of event", user_id INT COMMENT "id of user", device_code INT COMMENT "device of ", channel INT COMMENT "")DUPLICATE KEY(event_time, event_type)DISTRIBUTED BY HASH(user_id) BUCKETS 8
这是一个创建名为"detail"的数据库表的SQL语句。该表包含以下列:
event_time:事件时间,数据类型为DATETIME,不能为空。event_type:事件类型,数据类型为INT,不能为空。user_id:用户ID,数据类型为INT。device_code:设备代码,数据类型为INT。channel:通道,数据类型为INT。此外,该表还具有以下约束:
使用 DUPLICATE KEY 子句,确保在event_time和event_type上的唯一性。使用 DISTRIBUTED BY HASH(user_id) BUCKETS 8进行分桶存储,将数据分布在8个桶中,根据user_id的哈希值进行分布。注意:这里我们指定了 event_time 和 event_type 为排序键,这里的排序键需要按照建表时的排序顺序来,排序键必须从建表语句的第一列开始!
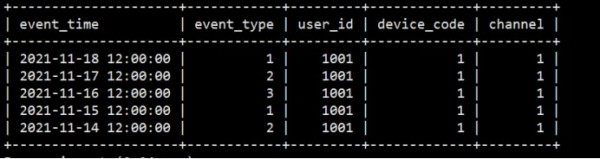
INSERT INTO detail VALUES('2021-11-18 12:00:00.00',1,1001,1,1); INSERT INTO detail VALUES('2021-11-17 12:00:00.00',2,1001,1,1); INSERT INTO detail VALUES('2021-11-16 12:00:00.00',3,1001,1,1); INSERT INTO detail VALUES('2021-11-15 12:00:00.00',1,1001,1,1); INSERT INTO detail VALUES('2021-11-14 12:00:00.00',2,1001,1,1);
查询明细数据,这种模型用来存储所有历史明细数据(和 MySQL、Hive的使用没什么两样):
有些场景我们不希望看到明细,而是希望看到一些聚合的结果(比如用户的下单总金额),那么就可以使用聚合模型来建表。
建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。在分析统计和汇总数据时,聚合模型能够减少查询时所需要处理的数据,提升查询效率。
在数据分析中,很多场景需要基于明细数据进行统计和汇总,这个时候就可以使用聚合模型了。比如:统计app访问流量、用户访问时长、用户访问次数、展示总量、消费统计等等场景。
适合聚合模型来分析的业务场景有以下特点:
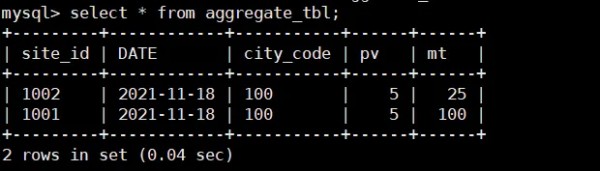
业务方进行查询为汇总类查询,比如sum、count、max不需要查看原始明细数据老数据不会被频繁修改,只会追加和新增CREATE TABLE IF NOT EXISTS aggregate_tbl ( site_id LARGEINT NOT NULL COMMENT "id of site", DATE DATE NOT NULL COMMENT "time of event", city_code VARCHAR(20) COMMENT "city_code of user", pv BIGINT SUM DEFAULT "0" COMMENT "total page views", mt BIGINT MAX ) DISTRIBUTED BY HASH(site_id) BUCKETS 8;
上面的表我们根据 site_id 进行了分组,分别进行聚合计算。
INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,5); INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,10); INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,15); INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,100); INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,20); INSERT INTO aggregate_tbl VALUES(1002,'2021-11-18 12:00:00.00',100,1,5); INSERT INTO aggregate_tbl VALUES(1002,'2021-11-18 12:00:00.00',100,3,25); INSERT INTO aggregate_tbl VALUES(1002,'2021-11-18 12:00:00.00',100,1,15);
建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。相对于明细模型,更新模型简化了数据导入流程,能够更好地支撑实时和频繁更新的场景。
有些分析场景之下,数据需要进行更新比如拉链表,StarRocks则采用更新模型来满足这种需求,比如电商场景中,订单的状态经常会发生变化,每天的订单更新量可突破上亿。这种业务场景下,如果只靠明细模型下通过delete+insert的方式,是无法满足频繁更新需求的,因此,用户需要使用更新模型来满足分析需求。但是如果用户需要更加实时/频繁的更新操作,建议使用主键模型。
使用更新模型的场景特点:
已经写入的数据有大量的更新需求(历史数据)需要进行实时数据分析CREATE TABLE IF NOT EXISTS update_detail ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) DISTRIBUTED BY HASH(order_id) BUCKETS 8
插入测试数据,注意:现在是指定create_time和order_id为唯一键,那么相同日期相同订单的数据会进行覆盖操作
INSERT INTO update_detail VALUES('2011-11-18',1001,1,1000);
继续插入一条 create_id 和 order_id 相同的数据:
INSERT INTO update_detail VALUES('2011-11-18',1001,2,2000);
查询:
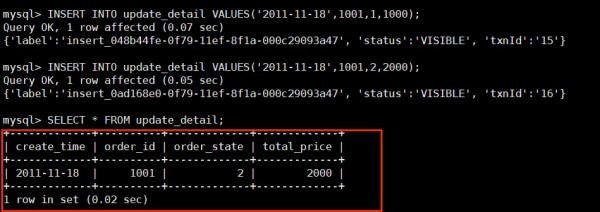
可以看到,如果日期和订单相同则会进行覆盖操作。
2.4.4、主键模型StarRocks 1.19 版本推出了主键模型 (Primary Key Model) 。建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。相对于更新模型,主键模型在查询时不需要执行聚合操作,并且支持谓词和索引下推,能够在支持实时和频繁更新等场景的同时,提供高效查询。
为什么有了更新模型还要有主键模型呢?其实主键模型相当于更新模型的一个升级版本。相比较更新模型,主键模型可以更好地支持实时/频繁更新的功能。虽然更新模型也可以实现实时对数据的更新,但是更新模型采用Merge on Read读时合并策略会大大限制查询功能,在主键模型更好地解决了行级的更新操作。配合Flink-connector-starrocks可以完成Mysql CDC实时同步的方案。
需要注意的是:由于存储引擎会为主键建立索引,导入数据时会把索引加载到内存中,所以主键模型对内存的要求更高,所以不适合主键模型的场景还是比较多的。
目前比较适合使用主键模型的场景有这两种:
数据冷热特征,比如最近几天的数据才需要修改,老的冷数据很少需要修改,比如订单数据,老的订单完成后就不在更新,并且分区是按天进行分区的,那么在导入数据时历史分区的数据的主键就不会被加载,也就不会占用内存了,内存中仅会加载近几天的索引。大宽表(数百列数千列),主键只占整个数据的很小一部分,内存开销比较低。比如用户状态/画像表,虽然列非常多,但总的用户数量不大(千万-亿级别),主键索引内存占用相对可控。原理:由于更新模型采用Merge策略,使得谓词无法下推和索引无法使用,严重影响查询性能。所以主键模型通过主键约束,保证同一个主键仅存一条数据的记录,这样就规避了Merge操作。
StarRocks收到对某记录的更新操作时,会通过主键索引找到该条数据的位置,并对其标记为删除,再插入一条数据,相当于把update改写为delete+insert
CREATE TABLE users ( user_id BIGINT NOT NULL, NAME STRING NOT NULL, email STRING NULL, address STRING NULL, age TINYINT NULL, sex TINYINT NULL ) PRIMARY KEY (user_id) DISTRIBUTED BY HASH(user_id) BUCKETS 4
测试数据:
INSERT INTO users VALUES(1001,'张三','[email protected]','AAA',17,'0'); INSERT INTO users VALUES(1001,'李四','[email protected]','BBB',18,'1'); INSERT INTO users VALUES(1002,'aaa','[email protected]','aaa',18,'0'); INSERT INTO users VALUES(1002,'bbb','[email protected]','bbb',18,'1');
查询结果:
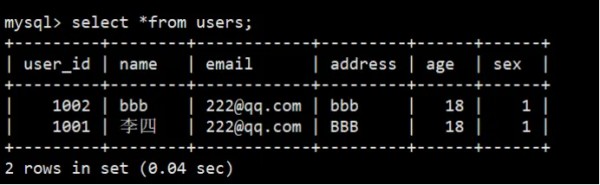
我们在上面的四个模型中其实已经用过了。
StarRocks中为加速查询,在内部组织并存储数据时,会把表中数据按照指定的列进行排序,这部分用于排序的列(可以是一个或多个列),可以称之为Sort Key。明细模型中Sort Key就是指定的用于排序的列(即 DUPLICATE KEY 指定的列),聚合模型中Sort Key列就是用于聚合的列(即 AGGREGATE KEY 指定的列),更新模型中Sort Key就是指定的满足唯一性约束的列(即 UNIQUE KEY 指定的列)。下图中的建表语句中Sort Key都为 (site_id、city_code)。
CREATE TABLE site_access_duplicate(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
DUPLICATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
CREATE TABLE site_access_aggregate(
site_id INT DEFAULT '10',
city_code SMALLINT,
pv BIGINT SUM DEFAULT '0')
AGGREGATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
CREATE TABLE site_access_unique(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
UNIQUE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
三种表对应的sort key都为site_id,city_code。创建排序列需要注意以下两点:
(1)排序列的定义必须出现在建表语句中其他列的定义之前。以图5.1中的建表语句为例,三个表的排序列可以是site_id、city_code,或者site_id、city_code、user_name,但不能是city_code、user_name,或者site_id、city_code、pv。
(2)排序列的顺序是由create table语句中的列顺序决定的。DUPLICATE/UNIQUE/AGGREGATE KEY中顺序需要和create table语句保持一致。以site_access_duplicate表为例,也就是说下面的建表语句会报错。
-- 错误的建表语句
CREATE TABLE site_access_duplicate(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
DUPLICATE KEY(city_code, site_id)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
-- 正确的建表语句
CREATE TABLE site_access_duplicate(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
DUPLICATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
使用时注意事项(并不是说建了排序键就会提升查询效率,取决于查询语句):
(1)用户查询时如果条件包含上述两列,则可以大幅地降低扫描数据行,如:
select sum(pv) from site_access_duplicate where site_id = 123 and city_code = 2;
(2)如果查询只包含site_id一列,也能定位到只包含site_id的数据行,如:
select sum(pv) from site_access_duplicate where site_id = 123;(只用到了排序键的第一位同样可以优化)
(3)如果查询只包含city_code一列,那么需要扫描所有的数据行,排序的效果相当于大打折扣,如:select sum(pv) from site_access_duplicate where city_code = 2; //使用时和mysql索引规则一样,缺少最佳左前缀原则,索引会失效
使用排序键本质就是在进行二分查找,所以排序列指定的越多,那么消耗的内存也会越大,StarRocks为了避免这种情况发生也对排序键做了限制:
shortkey 的列只能是排序键的前缀;shortkey 列数不超过3;字节数不超过36字节;不包含FLOAT/DOUBLE类型的列;VARCHAR类型列只能出现一次, 并且是末尾位置;当shortkey index的末尾列为CHAR或者VARCHAR类型时, shortkey的长度会超过36字节;当用户在建表语句中指定PROPERTIES {short_key = "integer"}时, 可突破上述限制;2.4.6、物化视图Materialized Views 表:简称 MVs,物化视图
使用场景:
在实际的业务场景中,通常存在两种场景并存的分析需求:对固定维度的聚合分析 和 对原始明细数据任意维度的分析。
例如,在销售场景中,每条订单数据包含这几个维度信息(item_id, sold_time, customer_id, price)。在这种场景下,有两种分析需求并存:
业务方需要获取某个商品在某天的销售额是多少,那么仅需要在维度(item_id, sold_time)维度上对 price 进行聚合即可。分析某个人在某天对某个商品的购买明细数据。在现有的 StarRocks 数据模型中,如果仅建立一个聚合模型的表,比如(item_id, sold_time, customer_id, sum(price))。由于聚合损失了数据的部分信息,无法满足用户对明细数据的分析需求。如果仅建立一个 Duplicate 模型,虽可以满足任意维度的分析需求,但由于不支持 Rollup,分析性能不佳,无法快速完成分析。如果同时建立一个聚合模型和一个 Duplicate 模型,虽可以满足性能和任意维度分析,但两表之间本身无关联,需要业务方自行选择分析表。不灵活也不易用。
如何使用:
使用聚合函数(如sum和count)的查询,在已经包含聚合数据的表中可以更高效地执行。这种改进的效率对于查询大量数据尤其适用。表中的数据被物化在存储节点中,并且在增量更新中能和 Base 表保持一致。用户创建 MVs 表后,查询优化器支持选择一个最高效的 MVs 映射,并直接对 MVs 表进行查询而不是 Base 表。由于 MVs 表数据通常比 Base 表数据小很多,因此命中 MVs 表的查询速度会快很多。
创建物化视图:
CREATE MATERIALIZED VIEW test_detail_view AS SELECT user_id,MAX(event_type),COUNT(device_code),SUM(channel) FROM detail GROUP BY user_id;
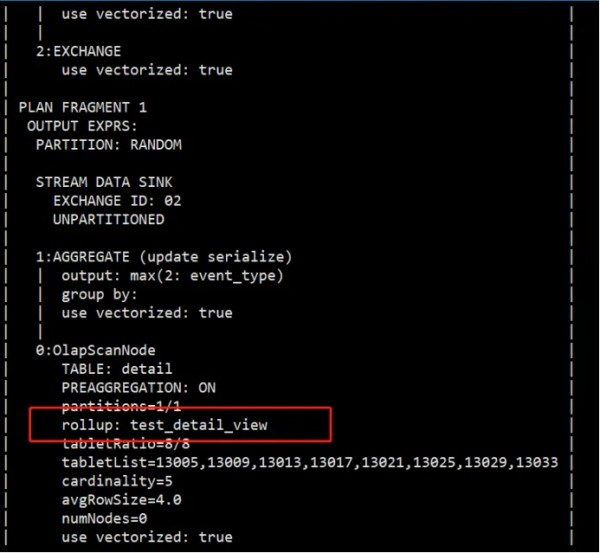
创建完视图后,我们并不能感知创建成功,可以通过explain来分析是否命中视图。可以看到上面物化视图对event_type字段使用max函数,那么rollup命中的数据源为创建的物化视图。
explain select max(event_type) from detail;
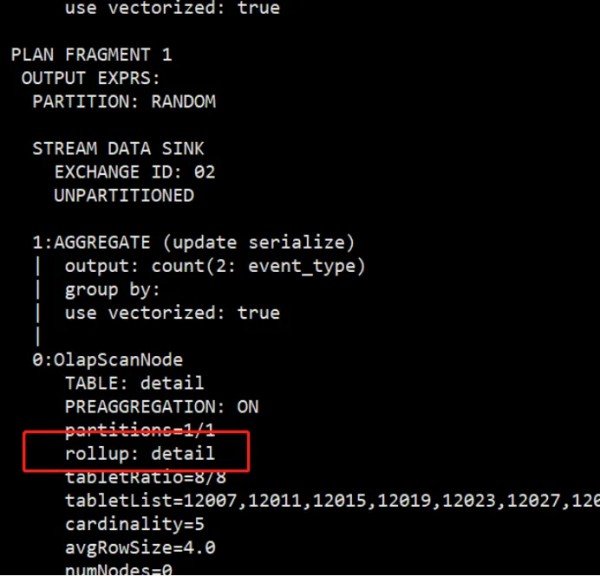
如果使用对event_type字段使用count函数,可以看到rollup命中的是detail表,而不是物化视图。
explain select count(event_type) from detail;
建立物化视图可以帮助用户对于不同场景都起到加速查询的作用。目前物化视图支持的函数如下有:count、max、min、sum、percentile_approx、hill_union、bitmap_union。
所以,如果使用了物化视图,那么我们在查询的时候就需要注意 SQL 中的字段是否能对应上创建的物化视图中字段的函数。
StarRocks 【新一代MPP数据库】(3)https://developer.aliyun.com/article/1534283
相关实践学习
阿里云百炼xAnalyticDB PostgreSQL构建AIGC应用
通过该实验体验在阿里云百炼中构建企业专属知识库构建及应用全流程。同时体验使用ADB-PG向量检索引擎提供专属安全存储,保障企业数据隐私安全。
AnalyticDB PostgreSQL 企业智能数据中台:一站式管理数据服务资产
企业在数据仓库之上可构建丰富的数据服务用以支持数据应用及业务场景;ADB PG推出全新企业智能数据平台,用以帮助用户一站式的管理企业数据服务资产,包括创建, 管理,探索, 监控等; 助力企业在现有平台之上快速构建起数据服务资产体系
网址:StarRocks 【新一代MPP数据库】(2) http://www.mxgxt.com/news/view/1177230
相关内容
StarRocks:从概念到应用的下一代分析型数据库StarRocks 跨集群数据迁移:SDM 帮你一键搞定!
StarRocks数据立方体
StarRocks数据同步工具
StarRocks数据去重
StarRocks数据加密保护
StarRocks数据字典管理
StarRocks数据集成
快速上手StarRocks
StarRocks数据归档
随便看看
最新实时动态
- GUCCI四大经典元素 历史见证时尚宠儿
- 曹骏跺脚变装,时尚圈新宠儿的蜕变之路
- 周震南展现独特穿搭,登上两本时尚杂志封面成为时尚圈宠儿
- 谢娜鞠婧祎同款地珠造型:时尚圈新宠儿,你get了吗?
- 王俊凯为何被称时尚圈宠儿?
- 时尚宠儿王一雅生日,大半个名利场祝福庆生【明星】风尚中国网
- 米兰时装周结束还在比,肖战和李宇春一骑绝尘,蔡徐坤着装被嘲笑
- 为什么说杨幂是时尚界的宠儿?看到她的写真,网友:顿时爱了
- 亚洲IT Girl时代:那些身价过亿的时尚圈宠儿
- 时尚圈的宠儿秦岚的时装观
热点实时动态
- 11991
- 7380
- 7188
- 7026
- 6995
- 6704
- 6269
- 6091
- 6090
- 6071

