文章库
 一、星际争霸简介及AI历史《星际争霸》(英语:StarCraft)是暴雪娱乐制作发行的一款即时战略游戏。游戏描述了26世纪初期,位于银河系中心的三个种族在克普鲁星际空间中争夺霸权的故事。三个种族分别是:地球人的后裔人族(Terran)、一种进化迅速的生物群体虫族(Zerg),以及一支高度文明并具有心灵力量的远古种族星灵(Protoss)。《星际争霸》提供了一个游戏战场,用以玩家之间进行对抗。这也是该游戏以及所有即时战略游戏的核心内容。在这个游戏战场中,玩家可以操纵任何一个种族,在特定的地图上采集资源,生产兵力,并摧毁对手的所有建筑取得胜利。游戏同时为玩家提供了多人对战模式。AlphaStar并不是第一个挑战《星际争霸》的程序。AIIDE 星际争霸AI竞赛由加州大学圣克鲁斯分校在2010年首次举办,从此每年举办一场。这个比赛中大部分的AI都是以固定策略和手工规则为例,以2018年为例,排名第一的三星SAIDE,采用纯手写规则的人族机械化打法:开局先进行防守,中期开始寻找最佳时机进行Rush,用强力的一波带走对手;排名第二的是Facebook AI Research,其采用的方式是在比赛前根据与对手的交战历史训练出10几种模型,在比赛时采用LSTM模型判定当前局势下最优的策略,来回切换到对应的模型,当然,该方案也使用了大量的手工规则,例如农民分配、资源使用比例、队列生成、战斗部队走位等。二、关于AlphaStar2019年10月底,DeepMind在《自然》杂志发布最新研究:《Grandmaster level in StarCraft II using multi-agent reinforcement learning》,并放出大量AlphaStar和顶级人类选手的《星际争霸II》对战replay。相关数据显示,AlphaStar在战网上(欧服天梯)的排名已超越99.8%的活跃玩家,在不到 4 个月的时间里,它使用每个种族进行了 30 场天梯比赛,三个种族的水平都达到了宗师级别:星灵 6275 分(胜率 83%),人族 6048 分(胜率 60%),虫族 5835 分(胜率 60%)。
一、星际争霸简介及AI历史《星际争霸》(英语:StarCraft)是暴雪娱乐制作发行的一款即时战略游戏。游戏描述了26世纪初期,位于银河系中心的三个种族在克普鲁星际空间中争夺霸权的故事。三个种族分别是:地球人的后裔人族(Terran)、一种进化迅速的生物群体虫族(Zerg),以及一支高度文明并具有心灵力量的远古种族星灵(Protoss)。《星际争霸》提供了一个游戏战场,用以玩家之间进行对抗。这也是该游戏以及所有即时战略游戏的核心内容。在这个游戏战场中,玩家可以操纵任何一个种族,在特定的地图上采集资源,生产兵力,并摧毁对手的所有建筑取得胜利。游戏同时为玩家提供了多人对战模式。AlphaStar并不是第一个挑战《星际争霸》的程序。AIIDE 星际争霸AI竞赛由加州大学圣克鲁斯分校在2010年首次举办,从此每年举办一场。这个比赛中大部分的AI都是以固定策略和手工规则为例,以2018年为例,排名第一的三星SAIDE,采用纯手写规则的人族机械化打法:开局先进行防守,中期开始寻找最佳时机进行Rush,用强力的一波带走对手;排名第二的是Facebook AI Research,其采用的方式是在比赛前根据与对手的交战历史训练出10几种模型,在比赛时采用LSTM模型判定当前局势下最优的策略,来回切换到对应的模型,当然,该方案也使用了大量的手工规则,例如农民分配、资源使用比例、队列生成、战斗部队走位等。二、关于AlphaStar2019年10月底,DeepMind在《自然》杂志发布最新研究:《Grandmaster level in StarCraft II using multi-agent reinforcement learning》,并放出大量AlphaStar和顶级人类选手的《星际争霸II》对战replay。相关数据显示,AlphaStar在战网上(欧服天梯)的排名已超越99.8%的活跃玩家,在不到 4 个月的时间里,它使用每个种族进行了 30 场天梯比赛,三个种族的水平都达到了宗师级别:星灵 6275 分(胜率 83%),人族 6048 分(胜率 60%),虫族 5835 分(胜率 60%)。 论文链接:https://www.nature.com/articles/s41586-019-1724-z三、从AlphaGo到AlphaStar
论文链接:https://www.nature.com/articles/s41586-019-1724-z三、从AlphaGo到AlphaStar在此之前,DeepMind 开发的AlphaGo已经在围棋中击败了人类,但《星际争霸II》远比围棋复杂。
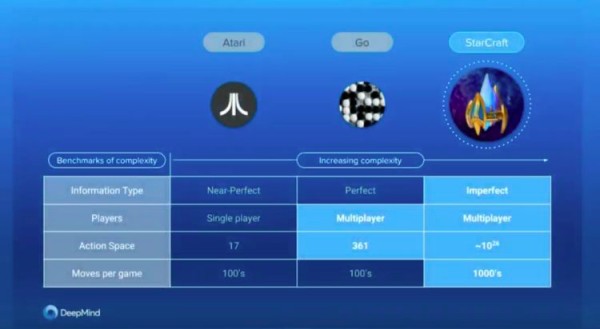
● 计算复杂度
在围棋比赛中,棋子一共只有 361 个落点,而在《星际争霸2》中,每个单位可以选择 300 多项基本行动。结合屏幕的每个可操作像素,其复杂度可能达到10的26次方。● 信息完备度
在围棋比赛中,AI可以看到人类对手的每一步行动和全部的棋盘,对于AI来说所有信息都是完备。而在《星际争霸II》中,由于“战争迷雾”的存在,AI接收的信息是不完备的,如果要获取更多信息需要依靠单位移动或者单位探测功能。不完备信息推理是限制AI智能化的一个很大因素。● 策略博弈度
在围棋比赛中,在某一个时刻,可能会存在“最优解”的策略。而在《星际争霸II》中,策略的优势是相对的,是互相克制的,可能多轮更新后的策略会被对手最初的策略所克制。四、AlphaStar人机对战限制由于AlphaStar是基于《星际争霸II》接口开发的,可以借助API达到远超人类的能力。为了尽可能公平地进行比赛,DeepMind对AlphaStar进行了以下限制。● 战争迷雾
《星际争霸》内置的AI Bot,关闭了战争迷雾,意味着你的一举一动都在电脑的实时监控中。● APM(Action Per Minute,每分钟操作次数)
早期版本的AlphaStar被严重质疑的一点是其APM疯狂地达到1500左右,要知道世界顶级选手也只有500上下。(鄙人年轻的时候大概在100左右……)
最后版本以一个人类选手为参考做了限制:最多在 5 秒内完成 22 个不重复指令,操作延迟限定在 110 毫秒左右。● 信息采集
在有视野的情况下,API可以快速获取视野内的所有环境信息。这点对人类来说是极不公平,毕竟人类需要从感知转认知。所以AlphaStar号称也做了类似操作(强烈表示怀疑…..)。五、AlphaStar人类职业选手优劣势对比● 记忆及计算能力AI可以精准地记得过往视野内的所有建筑和单位信息,并进行精确计算,这点是人类远达不到。
● 微操虽然AlphaStar限制了APM,但实际上并不妨碍其操作上的优势,人类选手太多无效操作和不精准操作(手抖),例如某一局PvT比赛中,AlphaStar使用6架凤凰战机瞬间同时举起对方单位......
● 多线操作在后期的大规模团战(各种技能)、空投骚扰、开新矿并行的情况下,AI可以随意碾压人类。
● 战术创意AlphaStar目前是基于有监督学习(大量人类选手比赛)的方式,基本上没有战术创意的概念。
● 全局战略AlphaStar在态势对应上,大多是以“经验”或“经验组合”驱动,审时度势能力较弱。例如对方空投,是分兵还是就近造单位,不一定是最优选择。
总体上看,AlphaStar和人类各有优势,目前可以通过其计算能力和无限学习人类选手战术来打败大部分人类。
六、AlphaStar核心技术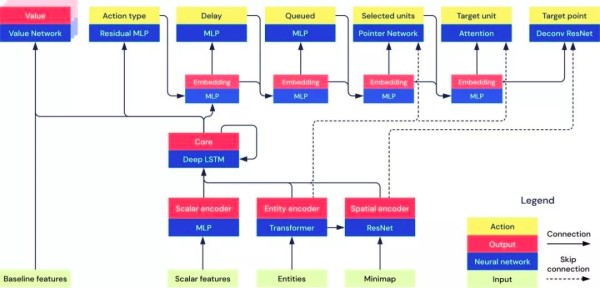
AlphaStar架构图
AlphaStar的技术原理在几篇论文和youtube的频道上已经有不少解析,这里我们只讨论一些可以在军事作战指挥中参考的关键技术。● 先验知识
论文中没有对AlphaStar的先验知识体系进行深入描述,网上有些文章说AlphaStar是零先验的,这点比较扯淡。先验知识包括建筑信息、建筑依赖关系、单位信息、兵种相克信息等。例如,星灵中的折跃门,要从零先验去学习并且达到比较好的效果,难度是相当大的,而且也浪费TPU。● 深度LSTM核
AlphaStar使用LSTM网络捕捉长程信息,跟踪所有之前发生的动作,以及过去访问的所有视图的位置。每个智能体使用一个深度 LSTM,每个 LSTM 有 3 个层和 384 个单元。AlphaStar 在游戏中每做出一个动作,该记忆就会更新一次。平均每个游戏会有 1000 个动作。网络大约有 7000 万个参数。● 图神经网络
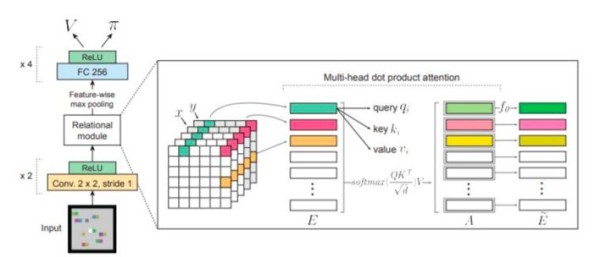
通过使用关系性深度强化学习,可以通过结构化感知和关系推理提高常规方法的效率、泛化能力和可解释性。在AlphaStar用于抽取非结构化信息以及提高策略模型可解释性。可解释性是军事指挥决策系统的重要组成部分。
● 模仿学习
通过对人类选手的大量学习,制定初始化战略,寻找制胜的关键点。数据表明,通过这项学习,一开局就赢了84%的人类。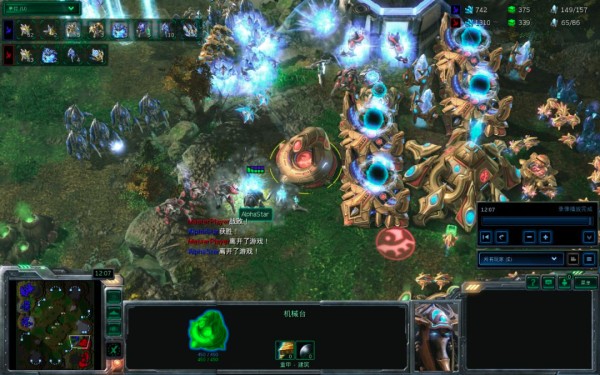 AlphaStar在防住对手Tower Rush后,直接拍下三矿扩大经济优势,最后获胜。
AlphaStar在防住对手Tower Rush后,直接拍下三矿扩大经济优势,最后获胜。● 联盟训练(群体强化学习)
《星际争霸II》的不完备博弈特点导致策略空间非常巨大,几乎不可能像棋类那样通过树搜索的方式确定一种或几种胜率最大的策略。一种战术策略总是会被别一种策略克制,关键是如何找到最接近纳什均衡的智能体。AlphaStar实现了一种联盟训练(league training)的方法,将初始化后每一代训练的智能体都放到这个联盟中。新一代的智能体需要和整个联盟中的其它智能体相互对抗,通过强化学习训练新智能体的网络权重。这样智能体在训练过程中会持续不断地探索策略空间中各种可能的作战策略,同时也不会将过去已经学到的策略遗忘掉。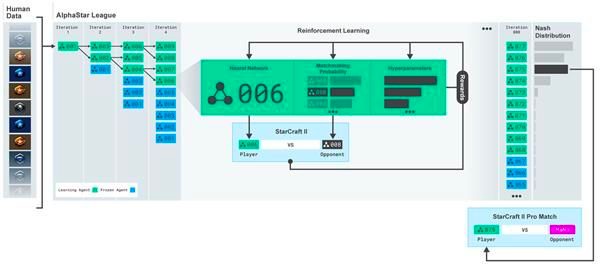
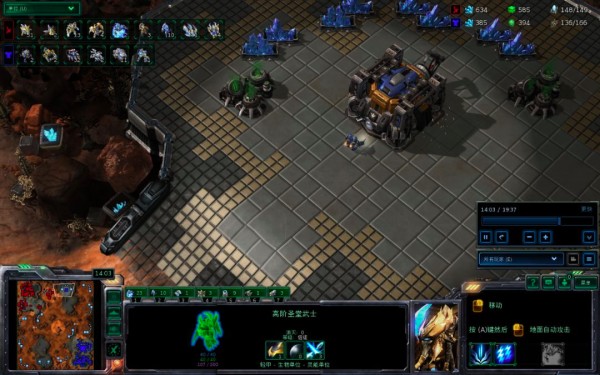
AlphaStar在对手旁边直接开分矿,最危险的地方就是最安全的地方……
● Off-policy强化学习
AlphaStar使用一个新的off-policy强化学习算法,里面包含了经验重播(ExperienceReplay),自我模仿学习(Self-ImitationLearning)以及策略蒸馏(PolicyDistillation)等等机制,用于保证训练的稳定性和有效性。
七、国防领域AI应用 DARPA的ACE(空战演进)项目
DARPA的ACE(空战演进)项目
人工智能在军事领域的主要应用体现在以下几个方向:
◆ 智能化感知与信息处理
◆ 智能化指挥控制辅助决策
◆ 无人化军用平台
◆ 仿生机器人
◆ 扩展人的体能技能和智能
DARPA(美国国防部高级研究计划局)于2010年启动“心灵之眼”(Mind’s Eye)项目,寻求使用人工智能进行视频分析,开发一种机器能力——视觉智能,提供观察区域中与活动相关信息,能够提前对时间敏感的重大潜在威胁进行分析。DARPA于2011年设立“洞悉”(Insight)项目,通过分析和综合各类传感器和其他来源的信息,集成烟囱式的信息形成统一的战场图像,发现威胁和无规律的战争行动。该项目用于增强分析人员实时从所有可用来源收集信息、从中学习以及与最需要的人分享重要信息的能力。2017年4月,美国五角大楼提出了Maven项目。美国军方在全球各地投放了大量无人机,这些无人机每日每时都传回海量的视频资料,军方分析师早已不堪重负。Maven的首要任务就是,利用人工智能技术,来识别无人机镜头中的车辆和其他物体,从而减轻分析人员的负担。2019年5月,DARPA提出“空战演进”(ACE)项目,将开展人工智能驱动的空中格斗竞赛,该局把其视为研发空对空自动作战软件的第一步。由人工智能控制的战斗机作战反应更快,可让飞行员有更多的时间管理更大的空中战场。最终,ACE项目将发展出可靠和可信的人工智能空中格斗软件,接管空对空作战任务。八、星际争霸II和军事作战指挥的比较
 九、第五代军事作战指挥系统的构建思路基于以上信息综合,一个智能的作战指挥系统至少要包括以下要素。
九、第五代军事作战指挥系统的构建思路基于以上信息综合,一个智能的作战指挥系统至少要包括以下要素。● 先验知识图谱(装备体系,战术战法,指挥艺术)
● 情报感知网络(接收各种输入)
● 多智能体策略网络(例如无人机集群的协同AI)
● 态势评估价值网络(评估当前局势)
● 基于图神经网络的推理解释引擎
● 基于深度长短记忆的指控决策网络
● 基于群体强化学习的兵棋推演
网址:文章库 http://www.mxgxt.com/news/view/1218666
相关内容
库洛姆(火焰之纹章)牛文书库
库存周转率还不会算?读这篇文章就够了!
【教学课件】第二章建构关系数据库.ppt
北大人文学科文库·中国文学研究丛书
文章
库里夫妇:青梅竹马,共谱人生华章
明星文章图片大全网站,一站式获取明星资讯与美图的新宠,明星资讯宝库,一站式明星文章与美图新平台,明星资讯美图库,一站式明星内容新平台
第89章 剧本资源库
一键生成万字长文 百度文库橙篇APP上线
随便看看
最新实时动态
- 初代网红转型当演员,却被多次吐槽“演啥都一样”
- 因长相爆红网络草根名人(6)
- 冯提莫转型成功,从网红走向明星的传奇蜕变
- 草根演员李嘉明:从片酬逆袭,转型成直播网红,草根也能翻身!
- 从网红到演员,蜕变最成功,走路最踏实的可能也只有他了
- 广州严打造星骗局!星探搭讪竟是套路?
- 蔡少芬(中国香港女演员,模特)
- “神似韩素希宋慧乔”的韩国知名男星女友,进军演艺圈演员出道
- “淘宝模特”出身的4位明星,宋威龙胡一天还好,图4一眼误终身
- 模特出道,沉淀12年才成名的彭冠英,为何不算火却是很多人的偶像
热点实时动态
- 12031
- 7397
- 7202
- 7041
- 7007
- 6718
- 6283
- 6105
- 6105
- 6087

