刚刚,DeepSeek开源FlashMLA,推理加速核心技术,Star量飞涨中

机器之心报道
机器之心编辑部
上周五,DeepSeek 发推说本周将是开源周(OpenSourceWeek),并将连续开源五个软件库。
第一个项目,果然与推理加速有关。
北京时间周一上午 9 点,刚一上班(同时是硅谷即将下班的时候),DeepSeek 兑现了自己的诺言,开源了一款用于 Hopper GPU 的高效型 MLA 解码核:FlashMLA。

该项目上线才 45 分钟就已经收获了超过 400 star!并且在我们截图时,Star 数量正在疯狂飙升。
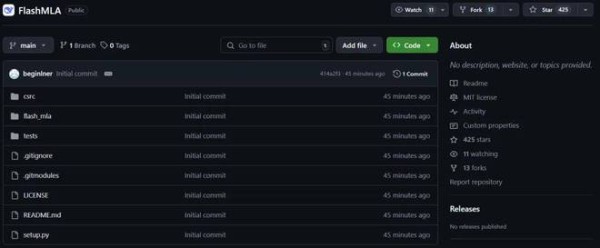
项目地址:https://github.com/deepseek-ai/FlashMLA
众所周知,MLA是DeepSeek大模型的重要技术创新点,主要就是减少推理过程的KV Cache,从而实现在更少的设备上推理更长的Context,极大地降低推理成本。
此次 DeepSeek 直接开源了该核心技术的改进版本,可以说是诚意满满。
接下来,就让我看下这个开源项目的核心内容。
据介绍,FlashMLA 是适用于 Hopper GPU 的高效 MLA 解码内核,针对可变长度序列服务进行了优化。
目前已发布的内容有:
BF16块大小为 64 的分页 kvcache其速度非常快,在 H800 SXM5 GPU 上具有 3000 GB/s 的内存速度上限以及 580 TFLOPS 的计算上限。
在部署这个项目之前,你需要的有:
Hopper GPUCUDA 12.3 及以上版本PyTorch 2.0 及以上版本快速启动
安装python setup.py install
基准python tests/test_flash_mla.py
使用 CUDA 12.6,在 H800 SXM5 上,在内存绑定配置下实现高达 3000 GB/s,在计算绑定配置下实现 580 TFLOPS。
用法from flash_mla import get_mla_metadata, flash_mla_with_kvcache
tile_scheduler_metadata, num_splits = get_mla_metadata (cache_seqlens, s_q * h_q //h_kv, h_kv)
for i in range (num_layers):
o_i, lse_i = flash_mla_with_kvcache (
q_i, kvcache_i, block_table, cache_seqlens, dv,
tile_scheduler_metadata, num_splits, causal=True,
该项目发布后也是好评如潮。
甚至有网友打趣地表示:「听说第五天会是 AGI」。
最后,还是那句话:这才是真正的 OpenAI

特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
Notice: The content above (including the pictures and videos if any) is uploaded and posted by a user of NetEase Hao, which is a social media platform and only provides information storage services.
网址:刚刚,DeepSeek开源FlashMLA,推理加速核心技术,Star量飞涨中 http://www.mxgxt.com/news/view/1365051
相关内容
刚刚,DeepSeek开源FlashMLA,推理加速核心技术,Star量飞涨中“投降”还是“重生”?刚刚,百度官宣:搜索全面接入DeepSeek!
智工+DeepSeek=?中国首个工业大模型组合拳,工业智能落地加速
超级应用联姻DeepSeek “技术共同体式”互通成新趋向
【基金视界】DeepSeek持续引爆全球,概念股连掀涨停潮,不少明星基金经理提前布局
刚刚!美股,崩了
国内开源AI大模型对比:DeepSeek R1 对比通义千问Max
DeepSeek持续火爆 中国科技将重塑世界大模型市场格局
多地政务服务系统及中企巨头接入DeepSeek大模型,智能化转型加速
刚刚,DeepSeek揭秘R1官方同款部署设置,温度=0.6!OpenAI推理指南同时上线
随便看看
最新实时动态
- TFBOYS为何合体难?这三点原因不解决,恐再难同台演出
- 刘畊宏粉丝超5000万,含泪向粉丝致谢,却被人酸为了捞金
- 张杰谢娜有小baby了,大半个娱乐圈送来祝福,种种细节早露端倪!
- 梦回《亲爱的,热爱的》,杨紫连续四年为李现庆生,甜喊“阿现”
- 李宇春演唱会见证粉丝结婚 临场献歌送祝福
- 粉丝盛典明星夜,一场属于颜值党的舔屏盛宴
- 大型粉丝盛典,众多大咖明星云集,为爱助力、砥砺前行前行
- 万名粉丝共同见证“奥迪世界好声音”盛况
- 诚邀“铁杆粉丝”一起来见证
- 泫雅与龙俊亨甜蜜逛街被拍,粉丝见证浪漫瞬间!
热点实时动态
- 12133
- 7436
- 7238
- 7076
- 7041
- 6752
- 6316
- 6140
- 6140
- 6123

