刚刚,DeepSeek揭秘R1官方同款部署设置,温度=0.6!OpenAI推理指南同时上线
新智元报道
编辑:Aeneas 好困
【新智元导读】DeepSeek官方发布的R1模型部署指南来了!留言区纷纷高呼:「服务器繁忙」问题何时解决?同一天内,OpenAI的推理模型指南也发布了,特点就是字数很多。
同一天内,DeepSeek和OpenAI都发布了推理模型使用指南!
DeepSeek的X账号迎来久违的更新:发布了官方版本,教大家如何部署DeepSeek-R1的设置。
最佳方法如下——
注意,官方部署DeepSeek,使用的是跟开源版本完全相同的模型。
不过在留言区最热门的呼声,莫过于请DeepSeek尽快解决「服务器繁忙」的问题。
巧的是,就在同一天的早些时候,OpenAI也发布了官方指南,汇总了使用o系列模型的最佳实践。
包括推理模型与非推理模型之间的区别、何时使用推理模型、以及如何有效地使用提示来引导推理模型。
接下来,让我们详细看一下,两大明星AI机构的官方指南细节。
DeepSeek:手把手教你正确用上官方同款
如何部署和官方一样的DeepSeek-R1?
第一点:不要使用系统提示
请勿添加系统提示(system prompt),所有指令都应当包含在用户提示(user prompt)中。
第二点:将采样温度参数设置为0.6
将采样温度(temperature)设置在 0.5~0.7 之间(建议使用 0.6),以避免输出出现重复循环或语义不连贯的情况。
第三点:使用官方prompt
对于文件上传功能,DeepSeek建议按照模板创建提示,其中包含 {file_name}、{file_content} 和 {question} 这些参数。
对于网络搜索功能,则包含 {search_results}、{cur_data} 和 {question} 这些参数。
对于中文查询,使用如下提示:
对于英文查询,使用如下提示:
第四点:别让模型绕过思考
DeepSeek发现,DeepSeek-R1系列模型在回应某些查询时,可能会跳过思考过程(即直接输出空的思考标签「 \n\n 」),这会影响模型的推理性能。
为确保模型进行完整的推理过程,官方建议:强制要求模型在每次输出时都以思考标签「 \n」开始。
OpenAI:推理模型的最佳实践
在这边,OpenAI也放出使用o系列模型的最佳实践指南。
推理模型与GPT模型
OpenAI介绍道,与GPT模型相比,o系列模型在不同任务上表现出色,且需要使用不同的提示。
这两类模型没有优劣之分——它们各有所长。
o系列模型更像是一个「规划者」,能深入思考复杂任务;相比之下,GPT模型则是一个「执行者」,能直接执行任务,延迟低、性价比更高。
在不同情况下,具体选择哪个模型,推荐如下。
大多数AI工作流,可以使用二者的结合。
何时使用推理模型
OpenAI列出了一些从客户和内部观察到的成功使用模式,是一些针对o系列模型的实用指导。
1. 处理模糊任务
推理模型特别擅长处理信息有限或零散的情况,只需通过简单的提示词就能理解用户意图并妥善处理指令中的信息缺口。
值得注意的是,推理模型通常会在做出未经验证的猜测或填补信息空缺之前,主动提出澄清性问题。
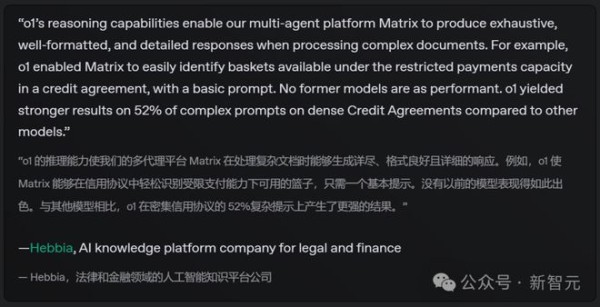
AI知识平台的法律和金融公司表示,只需一个简单提示,o1就能使Matrix轻松识别信用协议中受限支付能力下可用的资金篮。此前没有任何模型达到这种性能水平
2. 大海捞针
当需要处理大量非结构化信息时,推理模型特别擅长理解内容并精准提取出回答问题所需的关键信息。

比如,AI金融平台发现,为了分析一家公司的收购,o1审查数十份文件(合同和租赁协议),找到了可能影响交易的复杂条款
3. 在大型数据集中发现关系和细微差别
推理模型特别擅长分析包含数百页密集、非结构化信息的复杂文档,如法律合同、财务报表和保险索赔等。这些模型在识别文档之间的关联性,并基于数据中隐含的事实做出决策方面,表现尤为突出。

税务研究平台发现,o1在综合多个文档的推理上表现要好得多
推理模型还特别擅长理解细微的政策和规则,并将其准确应用于具体任务中以得出合理结论。

投资管理AI平台提问:融资如何影响现有股东,尤其是在行使反稀释权的情况下?o1和o3-mini完美完成任务,而顶级财务分析师需要花20-30分钟计算
4. 多步骤AI智能体规划
推理模型在AI智能体规划和策略制定中发挥着关键作用。
将推理模型作为「计划者」时效果显著:它能为问题制定详细的多步骤解决方案,并根据具体需求(高智能或低延迟)选择和分配合适的GPT模型(执行者)来完成各个步骤。

o1很擅长选择数据类型,将大问题分解为小块
5. 视觉推理能力
截至目前,o1是唯一一个具备视觉处理能力的推理模型。
与GPT-4o相比,o1的独特优势在于它能够准确理解最具挑战性的视觉内容,包括结构不规则的图表和表格,以及质量欠佳的图片。

SafetyKit会自动化审核数百万种产品的风险与合规性,包括奢侈品仿制品、濒危物种以及受管制物品。最困难的图像分类任务上,o1达到了88%的准确性
可以看到,o1能够从复杂的建筑工程图纸中精确识别各类设施和材料,并生成完整的工程物料清单(BOM)。
最令人惊喜的发现是,o1能够自动关联不同图纸之间的信息:它可以将建筑图纸某页的图例信息正确应用到其他页面,而无需特别指示。
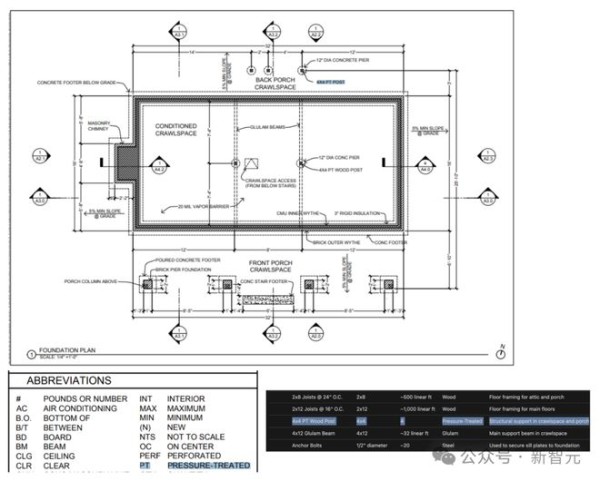
例如,在识别4x4 PT木柱时,o1 够根据图例自动理解「PT」代表压力处理
6. 代码审查、调试和质量改进
推理模型在审查和改进大规模代码方面表现突出。考虑到这类模型的较高延迟特性,通常将代码审查任务安排在后台运行。
虽然GPT-4o和GPT-4o mini凭借较低的延迟可能更适合直接编写代码,但在那些对延迟要求相对不那么严格的代码生成场景中,o3-mini表现同样出色。

Windsurf发现,o3-mini非常擅长计划和只需复杂的软件设计系统
7. 评估和基准测试其他模型的响应
OpenAI还发现,推理模型在对其他模型的输出进行基准测试和评估方面表现优异。
数据验证对确保数据集的质量和可靠性至关重要,这一点在医疗保健等敏感领域尤其重要。
传统验证方法主要依赖预设规则和模式,而o1和o3-mini等先进模型则能够理解上下文并进行数据推理,从而提供更灵活、更智能的验证方案。

在医疗应用场景中,o1的推理能力能在最困难和最复杂的评分任务中精准识别细微差异,彻底改变评估方式
如何编写推理模型的prompt
推理模型在处理简明直接的提示词时表现最佳。某些提示工程(如要求模型「一步一步思考」)可能并不会提升性能,有时反而会降低效果。
简单来说,你可以可以这样理解:
构建prompt的具体建议如下:
以下是代码重构、执行规划、STEM研究的prompt示例:
左右滑动查看
推理工作原理
推理模型在输入和输出token之外,还引入了推理token用于「思考」。
在生成推理token后,模型会生成可见的补全内容作为最终答案,同时从上下文中清除推理token。
下面是用户与AI助手之间多轮对话的示例。可以看到,每轮对话的输入和输出token都会被保留,而推理token则会被移除。
参考资料:
https://x.com/deepseek_ai/status/1890324295181824107
https://platform.openai.com/docs/guides/reasoning-best-practices
https://platform.openai.com/docs/guides/reasoning

海量资讯、精准解读,尽在新浪财经APP
网址:刚刚,DeepSeek揭秘R1官方同款部署设置,温度=0.6!OpenAI推理指南同时上线 http://www.mxgxt.com/news/view/1058608
相关内容
DeepSeek火爆全网,OpenAI首席执行官发声事关DeepSeek,硅谷大佬“互掐”!OpenAI又爆巨额融资
DeepSeek商标遭校友公司抢注,AI巨头纷纷接入引发热议
“DeepSeek恐慌袭击华尔街”
QQ 音乐自研“AI 助手”已部署满血版 DeepSeek
普通人如何用DeepSeek逆袭职场?这份清华“AI神器”指南免费领!
网易有道全面拥抱DeepSeek
DeepSeek持续火爆 中国科技将重塑世界大模型市场格局
变形金刚霸天虎成员大揭秘
启明星辰推出MASHFS:安全超融合服务引领DeepSeek本地化部署
随便看看
最新实时动态
- 赴山海 换脸 AI技术能否挽救危机?
- 危机公关培训走进九星包装集团
- 郭朗《房地产企业的舆论危机公关管理内训》
- 企业公关关系与危机管理
- 招商培训中教你要如何应对危机公关
- 舆情公关到底是什么?一篇全面深入的剖析
- 媒体公关与危机公关
- 顶流明星在澳门输了10亿?谣言背后竟是一场AI流量骗局!
- 谢霆锋经纪人霍汶希举家迁北京:抢旗下艺人风头,气质不输女明星
- 替身擦伤VS原著融梗,《漂白》剧组危机公关能打几分?
热点实时动态
- 11857
- 7365
- 7175
- 7013
- 6981
- 6691
- 6255
- 6078
- 6077
- 6057

